
The honest answer to whether self-hosting beats the OpenAI API on cost is this: it depends entirely on your volume, and self-hosted LLM cost wins past a certain point that you can calculate in about ten minutes. Below that point, the API is cheaper and easier. Above it, a fixed monthly server quietly saves you money every day. This guide hands you the method to find your own crossover, rather than a verdict that expires the next time anyone changes a price.
The real choice is not “API or server.” It is variable cost versus fixed cost. The API bills you per token, scaling smoothly from nothing to a fortune as you grow. A self-hosted model runs on a server that costs the same whether it answers ten requests or ten million. Knowing which shape fits your workload is the whole decision, so let us make it concrete.
The Two Models in Plain Terms
With the OpenAI API, you pay for every token in and every token out. There is no server to run, nothing to maintain, and the meter drops to zero the moment your traffic does. Someone else owns the expensive hardware and the headache of keeping it running. You trade money per request for total freedom from operations.
With a self-hosted model, you rent a server, install an open model on it, and run it yourself. The bill is flat and predictable. Your data never leaves your network. In exchange, you own the setup, the maintenance, and the quality ceiling of whatever model fits your machine.
The cleanest way to picture it: the API is a metered taxi, and self-hosting is owning a car. The taxi is perfect until you are commuting every day, at which point the meter starts to hurt and the fixed cost of ownership begins to win.
What Drives Self-Hosted LLM Cost
Self-hosted LLM cost has three real components, and only one of them is the server bill. The first is that flat monthly server. On the path most businesses can actually take today, that means CPU inference on a standard VPS, with no GPU involved, which keeps the cost low and the scope focused on small to mid-sized models. The second component is your time: the hours to set it up once, and a smaller ongoing trickle to keep it patched and running. The third is the quality ceiling you accept, because the model that fits your server may not match a frontier model.
What you stop paying for matters just as much. You stop paying per token, so a busy day costs the same as a quiet one. You stop sending your data to a third party. And you stop being exposed to the next pricing change, because your bill is your bill. For a steady workload, removing the meter is the entire point, and our budget local LLM guide covers the practical side of getting one running.
The Hidden Costs Nobody Counts
Both options carry costs that never appear on the headline price, and an honest comparison names them on both sides.
The API hides several. Rate limits become a real constraint at scale, throttling you exactly when you are busiest. Prices change, and your budget changes with them whether you planned for it or not. Every request sends your data out of your network, which some businesses simply cannot do. And the longer you build around one provider, the harder leaving becomes.
Self-hosting hides costs too, and pretending otherwise would be dishonest. Setup takes real hours the first time. Maintenance is small but never zero. A fixed server has a capacity ceiling, so a sudden traffic spike cannot be absorbed by someone else’s elastic cloud. And the open model you run will, on most tasks, trail the best commercial models by a noticeable margin. Counting these honestly is the only way to trust the comparison that follows.
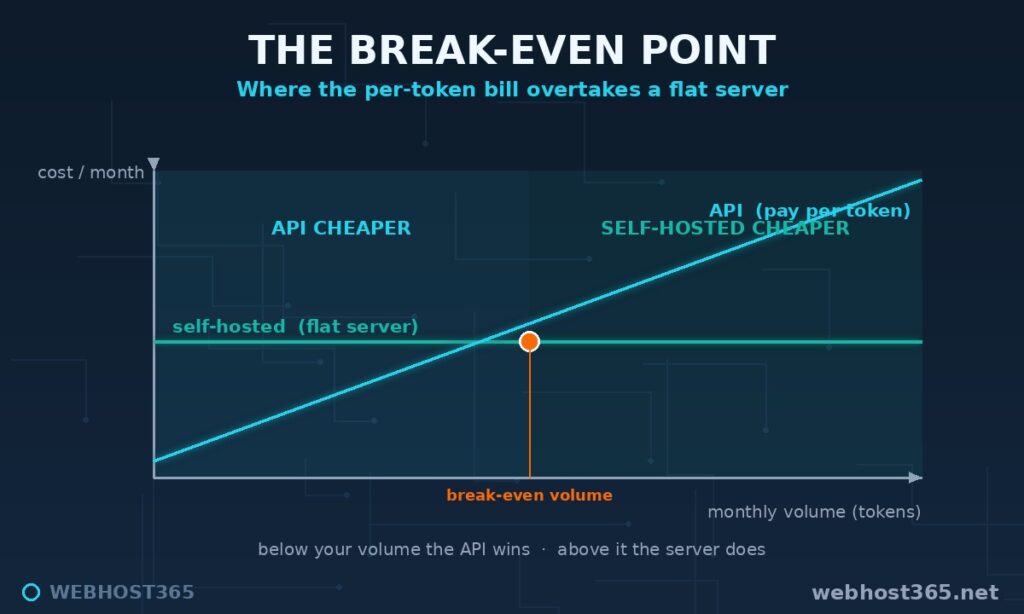
The Self-Hosted LLM Cost Break-Even Framework
Here is the method, and it is built to outlive any price change. You are looking for the crossover volume where your variable API bill grows past your fixed server cost. Three steps get you there.
First, estimate your monthly token volume:
Monthly tokens = requests per day × 30 × (avg tokens in + avg tokens out)Second, turn that into an API cost using whatever the rate is on the day you read this:
API cost per month = (monthly tokens ÷ 1,000,000) × current price per million tokensAlways look up the live rate rather than trusting a number in any article, including this one — pricing moves, and the current figures live on OpenAI’s pricing page. Third, compare that against the flat monthly cost of a server that runs an equivalent self-hosted model:
Self-hosted cost per month = the fixed VPS priceWhere those two numbers meet is your break-even. Below it, the API is cheaper. Above it, the server is. The beauty of the method is that it never goes stale: when prices change, you re-run step two with the new number and the crossover simply moves.
A Worked Example: The Support Bot
Picture an internal support assistant handling 3,000 requests a day, each averaging 1,500 tokens of input and 500 of output. The numbers below are illustrative — plug in your own — and the rates are examples only, accurate at the time of writing and worth re-checking.
Monthly tokens = 3,000 × 30 × 2,000 = 180 million tokensAt an example rate for a small, inexpensive model of around $0.50 per million tokens, that is roughly $90 a month on the API. Run the same workload through a mid-tier model at, say, $2 per million tokens, and it becomes about $360 a month. Now compare a self-hosted option: an m4.xlarge VPS with 8 cores and 16GB of RAM, at $79.99 a month, comfortably runs a quantised 7B model suited to this kind of structured support task.
The crossover is now visible. If a 7B-class model does the job, the $79.99 server beats the cheap API model once you cross roughly 160 million tokens a month, and it beats the mid-tier model far sooner, at around 40 million. Our example bot, at 180 million tokens, sits past both lines — self-hosting wins. A bot doing a tenth of that volume would sit below the line, and the API would be the smarter, cheaper choice. Same method, opposite answer, decided entirely by volume.
When the OpenAI API Wins
The API is genuinely the right call in several common situations, and choosing it is not a failure of nerve.
Low or spiky volume is the clearest case. If your usage is small or wildly uneven, scale-to-zero billing means you pay almost nothing during the quiet stretches, which no fixed server can match. and if you need genuine frontier quality — nuanced reasoning, broad world knowledge, the strongest available model — the API gives you access no single affordable server can. If you have no appetite for operations, the API removes the entire burden. And during early prototyping, when you are still discovering what you need, paying per request beats committing to infrastructure. For a great many small projects, the API is simply correct.
When Self-Hosted LLM Cost Wins
Self-hosted LLM cost pulls ahead when the workload turns steady and predictable. High, consistent volume is the headline case, where the meter would otherwise run all day. A predictable flat bill is its own reward for any team that has to forecast spend. Data that must stay in-house — for compliance, privacy, or policy — can make self-hosting not just cheaper but mandatory, regardless of the math.
And crucially, self-hosting wins when a smaller model is genuinely good enough. A large share of real production work is not frontier reasoning. It is classification, routing, extraction, retrieval for a RAG knowledge base, and moderate-volume generation — all of which a well-chosen small model handles well. When the task fits a model your server can run, the economics and the privacy both favour keeping it in-house, a pattern our guide to hosting AI applications explores across workloads.
The Quality Variable You Cannot Ignore
Cost is only half the decision, and ignoring the other half would mislead you. A 7B model running on a CPU is not a frontier model, and no amount of clever hosting changes that. So the real question is not “which is better” but “what does your task actually need?”
Define good enough by the job. Extraction, classification, routing, and retrieval tolerate smaller models gracefully — they are pattern tasks, not genius tasks. Nuanced reasoning, long-context synthesis, and broad general knowledge often do not, and there the gap to a frontier model is real and felt. The practical move is to test your actual task on a candidate open model before committing. The open models worth evaluating live on Hugging Face, and an afternoon of testing answers the quality question more reliably than any benchmark table.
Reducing Self-Hosted LLM Cost on a VPS
If the math points to self-hosting, a few choices keep self-hosted LLM cost low without a GPU in sight. RAM is the deciding spec, because the first question for any model is whether it fits in memory. Quantisation — running a model at reduced precision — shrinks it dramatically with little quality loss, turning a model that needed expensive hardware into one that fits a modest box.
The Linux VPS 365 ladder maps cleanly onto this. A small 3B model is happy on an 8GB plan; a 7B model finds its sweet spot at 16GB; a 13B model wants 32GB; and the larger 64GB and 128GB tiers open the door to 30B-class and even quantised 70B models for batch or low-concurrency work. The full hardware mapping, with throughput expectations for each model size, is its own subject — our dedicated guide to choosing a VPS for Ollama covers it tier by tier. Once it is running, you can also put the model to work with private AI automations in n8n. For the agent and automation side, self-hosted AI agents run comfortably alongside, and tools like Ollama make running the model itself a one-command affair. You can see the full plan ladder on the Linux VPS 365 page.
The 60-Second Decision
Four questions resolve most cases without re-reading anything above.
Is your volume steady and substantial, or low and spiky? Steady and substantial leans self-hosted; low and spiky leans API. Must your data stay in your own network? If yes, self-hosting moves to the front regardless of cost. Will a small or mid-sized model do the job? If yes, self-hosting is viable; if you truly need frontier quality, the API leads. And do you have any appetite for running a server? If none at all, the API removes that burden entirely.
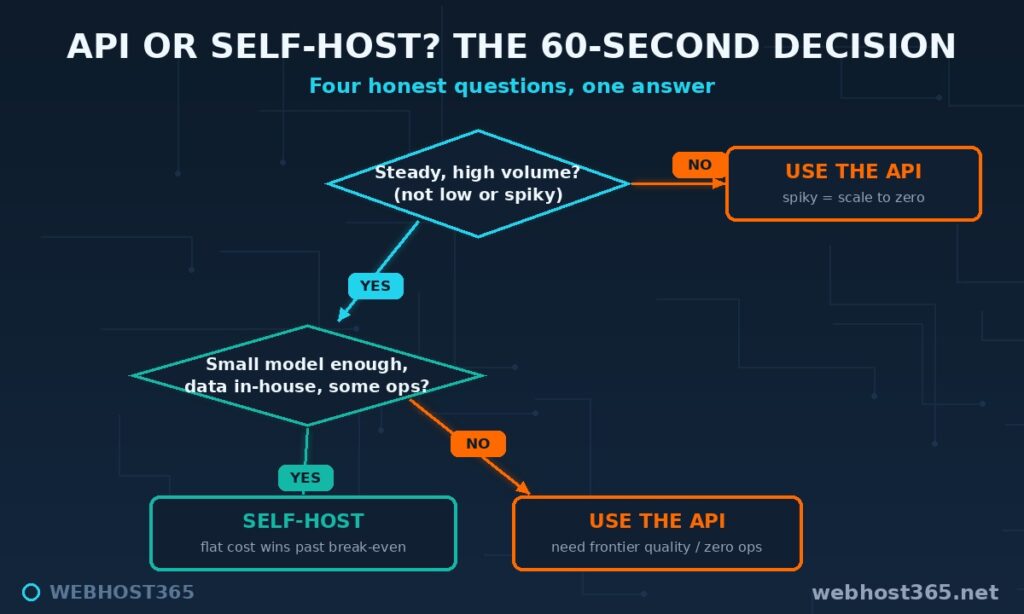
Add the answers up. Steady volume, sensitive data, a modest model, and some ops comfort point firmly at self-hosting. Spiky volume, no ops appetite, and a need for the very best model point just as firmly at the API. Most real decisions are not close once you answer honestly.
Frequently Asked Questions
It depends on volume. Below your break-even point the API is cheaper because you pay only for what you use; above it a flat-rate server wins because its cost does not rise with traffic. The break-even framework in this guide lets you calculate your own crossover in a few minutes.
When your monthly API bill for a given model exceeds the flat cost of a server that can run an equivalent open model. For a workload suited to a 7B model and a sub-$80 VPS, that crossover often falls somewhere between tens and low hundreds of millions of tokens a month, depending on the API rate you compare against.
Yes. Small and mid-sized models run on CPU, especially when quantised, and RAM is the main constraint rather than a graphics card. CPU inference suits steady, lower-concurrency workloads well; real-time chat for many simultaneous users is where a GPU still earns its keep.
Roughly, a 3B model fits 8GB of RAM, a 7B model fits 16GB, a 13B model fits 32GB, and 30B-to-70B quantised models need 64GB to 128GB. Larger RAM is the key that unlocks bigger models on a CPU-only server.
For pattern tasks like classification, extraction, routing, and retrieval, a good open model is often indistinguishable in practice. For nuanced reasoning and broad general knowledge, frontier commercial models still lead, so test your specific task before deciding.
Yes. A self-hosted model runs entirely within your own server, so prompts and responses never leave your network. This is often the deciding factor for businesses with compliance or confidentiality requirements, independent of cost.
Multiply your requests per day by 30, then by the average tokens per request (input plus output). A typical request runs from a few hundred to a few thousand tokens, so a short test on real traffic gives you a usable average to plug into the break-even formula.
Conclusion
There is no universal winner in the API-versus-self-hosting question, only your crossover point — variable cost below it, fixed cost above it. The teams who get this decision right are not the ones with the strongest opinion; they are the ones who spent ten minutes with the break-even math and answered honestly about their volume, their data, and the model quality their task actually needs.
If the numbers favour self-hosting, Linux VPS 365 starts at $4.99/mo and runs small models today, scaling all the way to 128GB of RAM when your models grow. Run your own break-even first, then pick the plan that sits on the right side of your line.